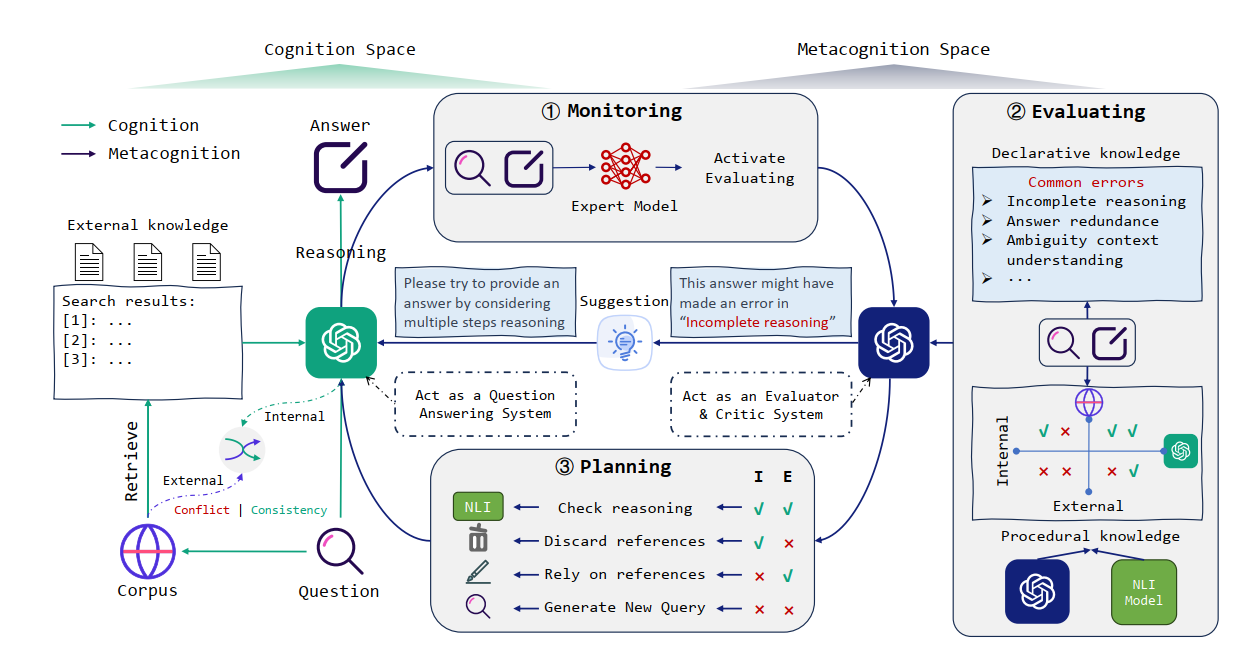
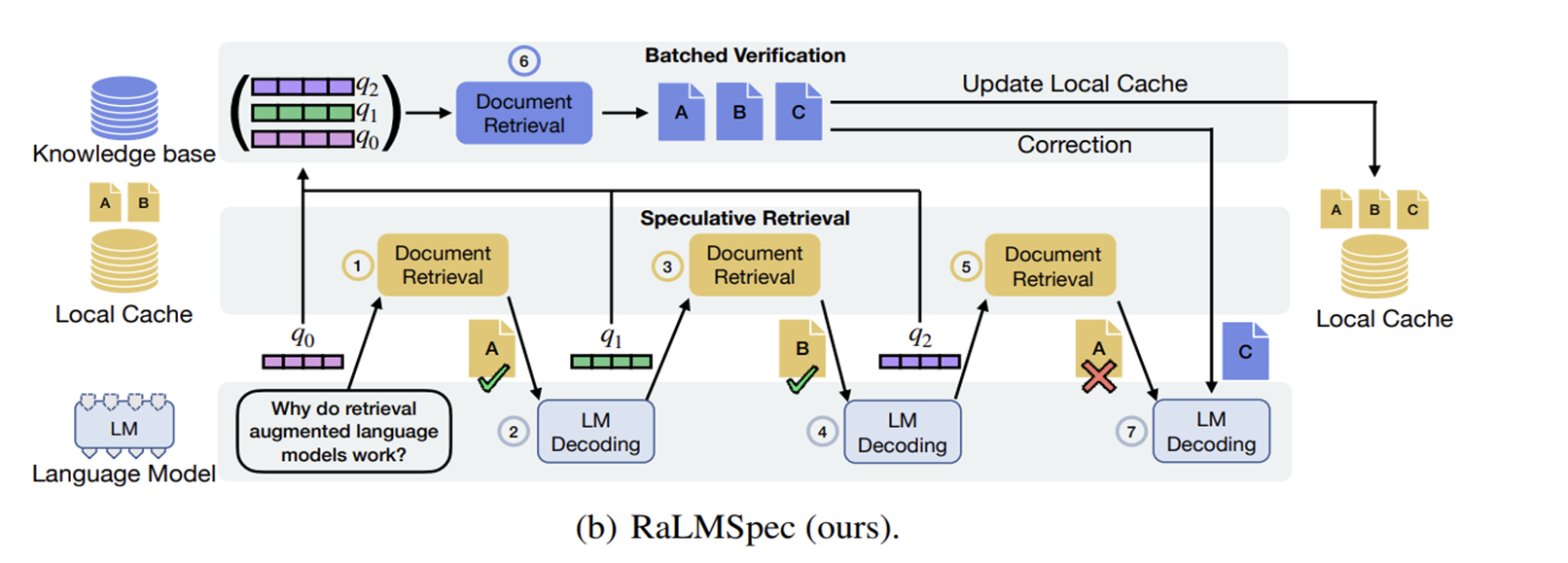
论文翻译:PaLM: 使用Pathways扩大语言模型(1) 2024-3-01 15:26 | 109 | 0 | 论文翻译 14728 字 | 58 分钟 谷歌是用什么方法训练出一个540B的模型的呢…… AIPaLM论文翻译