背景
自回归的大语言模型在各种自然语言处理任务上表现优秀,但是,他们需要大量的计算资源消耗。
大规模的自回归模型在解码时,如果要解码K个token,就需要串行K次,因为自回归模型是由前面的分布决定后面的分布的。除了这些大规模的自回归模型之外,还有更高效的、小型的模型(比如同系列的参数比较多的模型,和参数比较少的模型),这些模型可以更快地完成解码
Leviathan等人观察到,大型模型进行推理通常不是在算术运算上受到瓶颈,而是在内存带宽和通信上,因此可能会有额外的计算资源可用(大部分时间GPU都在干等)。这些额外的计算资源可以用来运行更高效的模型用于解码,从而在不损失生成质量的前提下实现对大语言模型的加速。
这种思想与分支预测比较类似——分支预测通过猜测哪一个指令电路会被执行,并且先一步执行这个电路,如果预测成功,可以节省相当的时间,如果预测失败,则退回预测之前的状态。Speculative Decoding(SD)的思想也是这样,利用GPU的空闲时间(其实也可以是CPU的空闲时间)运行一个更高效的小型模型(这个模型可能会犯错误,就像分支预测器一样)去猜测可能的解码结果是什么。如果猜对了,就省了计算资源,否则,也不会比原来更差——因为这个更高效的模型本身就是跑在被浪费的计算资源上的。
方法

SD利用一个规模较小的模型作为草稿,预测大模型的输出token,随后,大模型对输出token进行验证,从而达到减少大模型forward,节省并充分利用算力。
形式化表述
约定:
- $M_p$: Target Model(大模型),我们要加速的模型。其概率分布为 $p(x|x_{ \lt t})$。
- $M_q$: Draft Model(小模型),计算速度快但精度较低的模型。其概率分布为 $q(x|x_{ \lt t})$。
- $x_{ \lt t}$: 当前已生成的上下文序列。
- $K$: 每次投机生成的步数(Lookahead steps),即小模型一次生成多少个草稿 token。
SD通过让小模型串行生成多个token(但很快),随后让大模型并行进行验证(但很慢),在保证输出分布与$p(x|x_{ \lt t})$相同的情况下有着更快的生成速度。
为了理解SD,我们需要先了解拒绝采样原理。
拒绝采样原理
给定目标分布$p(x)$,我们希望从$p(x)$中取样$x \sim p(x)$,但是,$p(x)$由于计算成本过高等特点,难以直接采样,因此,我们改为从提议分布$q(x)$中采样,只要存在$M>0$,使得对于任意的$x$,都有:
$$ Mq(x) \ge p(x) $$
即,$q(x)$在扩大若干倍后可以完全在$p(x)$的上方,我们就可以利用$q(x)$去辅助$p(x)$采样。事实上,在SD场景下,我们一般设$M=1$。
我们需要证明,$\forall x_i \sim q(x)$,我们遵循以下步骤:
- 从 $U(0, 1)$ 中采样随机数 $u$
- 计算接受概率 $\alpha = \frac{p(x_i)}{Mq(x_i)}$
- 若 $ u \le \alpha$,接受$x_i$
- 否则,考虑修正分布 $\max(0, p(x) - q(x))$,我们从其中采样$x_i \sim (p(x) - q(x))$
这样得到的$x_i$满足 $x_i \sim p(x_i)$。
需要注意的是,这种表述不是标准的拒绝采样,我们称之为不退回的拒绝采样,对于标准的拒绝采样,它会在第4步退出,转而从原分布中重新采样,而我们则从修正分布$\max(0, p(x) - q(x))$中采样,因为如果$x_i$被拒绝,说明样本落在$q(x)>p(x)$的区域,我们必须要从这一部分采样弥补,这与从原分布中采样是等价的。
我们现在对这一命题给出证明。
设最终输出的样本为 $X$,$X$要么源自直接被接受的$q(x)$中采样的样本,这表明:
$$ P_1(x) = q(x) \min (1, \frac{p(x)}{q(x)}) $$
,要么源自从修正分布中采样的样本,此时,拒绝发生的总概率为 $P_{rej} = 1 - \sum_x \min(q(x), p(x))$,这表示采样点恰好落在 $q(x)$ 和 $p(x)$ 之间。此时,修正分布为
$$ p'(x) = \frac{\max(0, p(x) - q(x))}{\sum_x \max(0, p(x) - q(x)} $$
这一步可能稍微有些难理解,如果接受,那么$x_i$一定在目标分布$p(x)$中,否则,它必定在$p(x)$和$q(x)$之间,这个空隙就是
$$ \text{Gap}(x) = p(x) - \min(p(x), q(x)) $$
而 $p(x) - \min(p(x), q(x))=\max(0, p(x) - q(x)$,这表明:
$$ \text{Gap}(x) = \max(0, p(x) - q(x))) $$
由于此时是在采样为 $x$ 的时候被拒绝,根据条件概率公式:
$$ P(x|\text{拒绝}) = \frac{P(x; \text{拒绝})}{P(\text{拒绝})} $$
而 $P(x; \text{拒绝})$ 是从 $p(x)$ 和 $q(x)$ 的空隙中采样得到的,因此 $P(x; \text{拒绝}) = \max(0, p(x) - q(x))$。
而拒绝的情况就是对所有拒绝发生时的概率求和,这表明
$$ P(\text{拒绝}) = \sum_x \max(0, p(x) - q(x)) $$
这个总和实际上就是 p 和 q 两个分布之间的 $L_1$ 距离的一半。
综上,我们要么从 $P_1(x)$ 中采样,要么是 $p'(x)$,从而:
$$ P(x) = P_1(x) P(\text{接受}) + p'(x) P(\text{拒绝}) = q(x) \min (1, \frac{p(x)}{q(x)}) P(\text{接受}) + \frac{\max(0, p(x) - q(x))}{\sum_x \max(0, p(x) - q(x))} P(\text{拒绝}) $$,
如果 $p(x) \ge q(x)$,
$$ P(x) = q(x) + (p(x) - q(x)) = p(x) $$
,否则
$$ P(x) = q(x)\frac{p(x)}{q(x)} = p(x) $$
。
这样就证明了,通过这种方式从提议分布$q(x)$中采样的$x$满足$x \sim p(x)$。
Speculative Decoding 算法
我们已经证明了拒绝采样可以保障分布一致性,这样,我们可以正式提出拒绝采样算法:
输入:上下文 $x_{\lt t}$,投机步数 $\gamma$,目标模型 $M_p$ ,草稿模型 $M_q$
- 当未达到起草长度 $\gamma$,且生成 token 不是 EOS 时:
- 起草 token:
- 对于 $i=1,...,\gamma$:
- 采样 $x_{t+i-1} \sim q(x | x < t)$
- 记录该位置的概率分布 $q_i$
- 得到草稿序列 $\tilde{x} = [x_t, x_{t+1}, ..., x_{t + \gamma - 1}]$
- 对于 $i=1,...,\gamma$:
- 验证起草
- 将 $\tilde{x}$ 送入 $M_p$ 做一次 forward,得到概率分布 $[p_1, ..., p_\gamma, p_{\gamma+1}]
- 由 $p_i$ 和 $q_i$ 做拒绝采样:
- 接受:加入接受序列中
- 拒绝:从修正分布中采样,停止起草
- 结束验证
- 根据目标模型算出的分布采样额外token $x_{t+\gamma}$
- 同步上下文并回滚KVCache
这样,我们就实现了Speculative Decoding。
效率提升
平均 token 生成数
设每次生成的接受率 $\beta_{x \lt t}$ 代表对于前缀 $x \lt t$ 的接受率,假设这是一个独立同分布的变量,我们设 $\alpha = \mathbb{E}(\beta_{x \lt t}$ 为平均接受率。
那么,单次算法运行所生成的token数量 N 服从一个带上限的几何分布,其成功概率(即拒绝概率)为 1−α,上限为 γ+1,设 $N$ 为单次迭代生成的总token数。其生成的token总数的期望值为:
$$\mathbb{E}(N)=\frac{1-\alpha^{\gamma+1}}{1-\alpha}$$
证明过程如下:
设 $I_i$ 为第 $i$ 个位置产生token的指示随机变量,第 1 个token总是会产生:$P(I_1=1) = 1$,第 2 个token产生的条件是第 1 个被接受:$P(I_2=1) = \alpha$,第 $i$ 个token产生的条件是前 $i-1$ 个均被接受:$P(I_i=1) = \alpha^{i-1}$
因此,总期望为:
$$E(N) = \sum_{i=1}^{\gamma+1} P(I_i=1) = \sum_{i=1}^{\gamma+1} \alpha^{i-1}$$
上述各项构成一个首项为 1,公比为 $\alpha$,项数为 $\gamma + 1$ 的等比数列:
$$E(N) = 1 + \alpha + \alpha^2 + \dots + \alpha^\gamma$$
根据等比数列求和公式 $S_n = \frac{a_1(1-q^n)}{1-q}$:
$$E(N) = \frac{1 \cdot (1 - \alpha^{\gamma+1})}{1 - \alpha}$$
证明完毕。
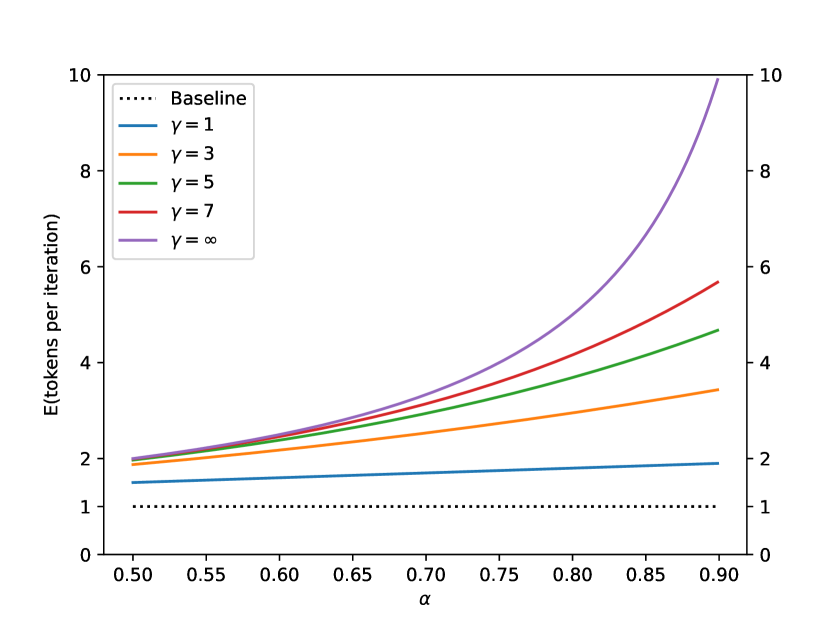
根据不同的 值,Speculative Decoding 预期的 token 数量与 的函数关系如上图。这给出了一个简单的推论,接受率总是越高越好。
接受率与模型差异的关系
前面的事情以后再来探索吧