原论文:Zhou, Y., Liu, Z., Jin, J., Nie, J. Y., & Dou, Z. (2024, May). Metacognitive retrieval-augmented large language models. In Proceedings of the ACM on Web Conference 2024 (pp. 1453-1463).
他们在Github上公开了MetaRAG的源代码。
原文摘要
检索增强生成技术(RAG)因其在生成事实内容方面的作用而成为自然语言处理的核心。虽然传统方法采用单次检索,但最近的方法已转向多跳推理任务的多次检索。但是,这些策略受预定义的推理步骤的约束,可能会导致响应生成不准确。本文介绍了MetaRAG,这是一种将RAG过程与元认知(Metacognition,对认知的认知)相结合的方法。在认知心理学中,元认知允许实体进行自我反思,并批判性地评估其认知过程。通过集成元认知,MetaRAG 使模型能够监控(monitoring)、评估(evaluating)和规划(Planning)其响应策略,从而增强其内省推理能力。通过三步元认知调节管道,该模型可以识别初始认知反应中的不足之处并加以修复。实证评估表明,MetaRAG的性能明显优于现有方法。
方法简析
概要
之前的各种方法虽然从各种地方改进了RAG的检索效果,但是这些方法中的检索步骤都是固定的。与此不同,我们人类可以反思并改进我们的思考方式,这种能力被称为元认知(Metacognition)。作者们认为,让RaLM(Retrieval-Augmented Language Model,i.e. 采用RAG的LLM)模拟人类的元认知能力,可以提高其在复杂任务上的表现。

如上图,人类的元认知可以分为两个部分:知识(Knowledge)和元认知知识(Metacognitive Knowledge),其中,知识表明我们对客观事实、方法等的认知,而元认知知识则是我们对认知过程的管理和调控,我们可以由元认知知识了解事物运行背后的逻辑,并由此找到自我提升的手段。向我们的输入会先由我们的知识部分得出一个响应,随后根据具体情况决定是否进入元认知部分进行分析,最终输出一个不错的响应。

仿照上文中人类的知识和元认知知识,作者将他们设计的LLM分为外部知识部分和元认知知识部分,给LLM一个输入,它会先像普通的RaLM一样从外部知识库中检索,并生成一个响应,随后由根据具体情况决定是否要进入元认知知识部分进行分析,最终输出一个还不错的响应。他们称这种方法为MetaRAG。
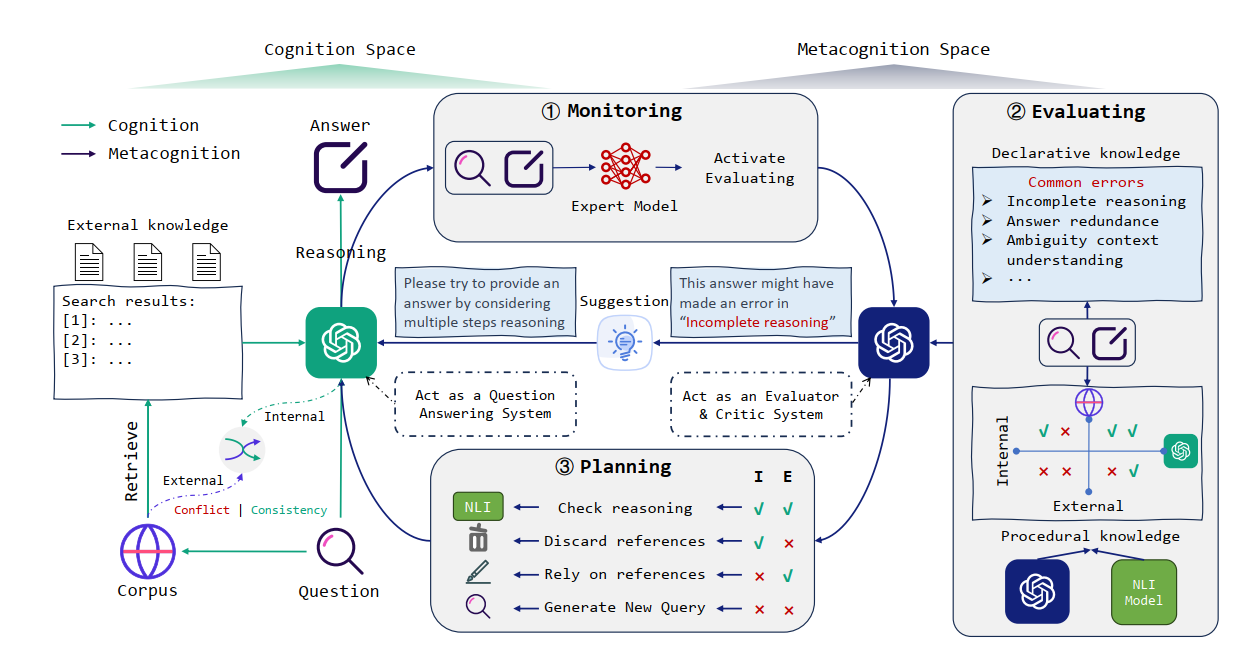
具体的,他们的方法可以归结为下图:

首先,他们将MetaRAG分作认知空间(Cognition Space)以及元认知空间(Metacognition Space),对应之前提到过的External Knowledge和Cognitive Knowledge。认知空间执行正常的RAG步骤。
元认知空间由Monitoring, Evaluating和Planning部分组成,其中,Monitoring部分负责评估回答质量,决定是否进入元认知空间,如果不进入,则按正常的RAG步骤输出,如果决定进入,则进入Evaluating部分,这一部分负责判断现有的内外知识是否足够解决问题,以及是由于犯了哪些错误导致回答质量不佳,随后的Planning阶段根据Evaluating阶段所得出的结论判断应该采取哪些操作提升回答的质量。
细节
Monitoring部分
如上文所说,Monitoring是负责评估回答的质量是否足够好的。对此,他们选择使用专家模型生成相同问题的回答,并通过对比LLM与专家模型的回答的相似度来决定答案是否足够好的。具体来说,他们将模型生成的嵌入与专家模型生成的嵌入作比较,如果相似性小于k,则认为这个答案是不好的。
(为什么他们不直接输出专家模型的结果呢?我也不知道,但是这个论文已经被A会接受了,或许大佬们认为这样做是没问题的?)
Evaluating部分
Evaluating是Monitoring认为答案不够好后进入的部分,主要聚焦于两点:
(a) 内部和外部知识来源都足以解决所提出的问题吗?
(b) QA LLM 的推理过程是否容易受到多跳 QA 中经常遇到的常见问题的影响?
为了解决这两个问题,他们又引入了两个概念:过程知识和陈述性知识。程序知识体现了对面对特定任务所必需的方法和策略的把握,而陈述性知识则锚定在特定事实或基于内容的信息中,涵盖与解决问题相关的事实和概念。他们在prompt中让模型充当evaluator-critic系统,认为这样做效果比让模型从问题的回答者去评估生成的答案要好。
在过程性知识的评估过程中,他们使用模型充当的evaluator-critic系统评估模型的内部知识,用NLI(自然语言推理)模型去衡量模型的外部知识,NLI模型可被抽象为形如 f(premise,hypothesis) 的函数,在premise可以推出hypothesis时返回1,否则返回0,同时,他们也给模型做了一个prompt:
Please act as an evaluator-critic system, determine if you can provide a reliable answer to the {question} based on your own knowledge?
判断完后,他们可以将知识上的不足分为四类,我们稍后会谈到。
在陈述性知识的评估过程中,他们将推理错误分为三类:不完全推理、答案冗余、歧义理解,并调用evaluator-critic系统去判断错误可能是什么,prompt如下:
Please act as an evaluator-critic system, assess whether the {response} based on {references} for the {question} contains any {error types}?
Planning部分
对错误有了认知后,就可以对症下药,尝试去解决错误了。现在填上文挖的坑,知识不足可以根据哪方面的知识来源不足被分为四类:
- 无知识
- 仅外部有
- 仅内部有
- 内部和外部都有
严格来说,最后一个不算知识不足,不过也属于可能的一种情形。无论如何,判断出来知识是哪方面不足后就可以对症下药了,对症生成prompt后,模型就可以从相应的地方继续搜索,直到问题解决或放弃为止。
知识不足不是模型回答错误的全部原因,另一种可能导致不准确回答的情况是内部和外部知识之间存在差异,即知识冲突,解决方案即直接放弃某个部分的知识,仅依赖单一知识来源就可以做出比较好的回答,不过他们这么做并没有考虑模型内部知识与外部知识的质量的差异,如果能考虑到评估知识库的质量,决定放弃某一个知识库可能会更好。
哪怕知识已经足够,模型可能还会在推理过程中犯错误,即错误推理,如果推理是用CoT等多步推理方法进行的,LLM会被要求重新检查推理过程中哪里可能出错,并对症重新进行推理。这里看起来似乎可以和ToT或者MCTS这样的方法结合一下,说不定会更好用呢?
评估部分
总体来说,
- MetaRAG 始终优于两个数据集的所有基线方法。与 Reflexion 相比,Reflexion 在其推理过程中还集成了自我批评机制,MetaRAG 在所有指标上都表现出了实质性的改进。这表明使用元认知策略比仅仅依靠自我批评更有益。
- 配备自我批评机制的模型与没有自我批评机制的模型相比,表现出优异的性能。
他们做了一个消融实验,证明剥离元认知空间中的任何一个组件都会造成效果的极大下降。
他们还研究了相似性阈值k,不过这些说起来也比较繁琐,在这里就不说了。
这篇理论上八月就看的差不多了,不过当时一直忙着没写完,现在才有时间写完发出来,不得不说我真的是……
