原文标题:ACCELERATING RETRIEVAL-AUGMENTED LANGUAGE MODEL SERVING WITH SPECULATION
Zhihao Zhang1†, Alan Zhu1, Lijie Yang1, Yihua Xu2, Lanting Li1, Hitchaya Mangpo Phothilimthana3, Zhihao Jia1‡
1Carnegie Mellon University, School of Computer Science
2 University of California, Berkeley 3 Google DeepMind
† zhihaoz3@andrew.cmu.edu,
‡ zhihao@cmu.edu
注:本文相当部分的内容是我根据自己的理解写的,如有错误,敬请谅解,也欢迎指正与讨论。
原文摘要:
检索增强语言模型 (RaLM) 已经证明了通过将非参数知识库与参数语言模型相结合来解决知识密集型自然语言处理 (NLP) 任务的潜力。RaLM 不是对完全参数化的模型进行微调,而是作用在低成本地适应最新数据和更好的源归因机制方面。在各种 RaLM 方法中,由于检索器和语言模型之间的交互更频繁,迭代 RaLM 提供了更好的生成质量。尽管有这些好处,但由于频繁的检索步骤,迭代 RaLM 通常会遇到高开销。为此,我们提出了 RaLMSpec,这是一个受推测启发的框架,它为迭代 RaLM 提供通用加速,同时通过推测检索和批量验证保留相同的模型输出。通过进一步结合预取、最优推测步幅调度器和异步验证,RaLMSpec 可以自动充分利用加速潜力。对于朴素迭代的RaLM服务,在4个下游QA数据集上对三种语言模型的广泛评估表明,当检索器为精确密集检索器、近似密集检索器和稀疏检索器时,RaLMSpec的加速比分别为1.75-2.39×、1.04-1.39×和1.31-1.77×与基线相比。对于 KNN-LM 服务,当检索器是精确的密集检索器和近似的密集检索器时,与baseline相比,RaLMSpec 可以实现高达 7.59× 和 2.45× 的加速比。
方法简析:
一般的RaLM从知识库中查找与用户输入相似度最高的文档(它们都会被转化成向量进行相似性比较),但是由于知识库中的文档数量很多,查找所需的时间长,所以迭代RaLM会因为冗长的查找流程而遇到堪忧的性能问题。

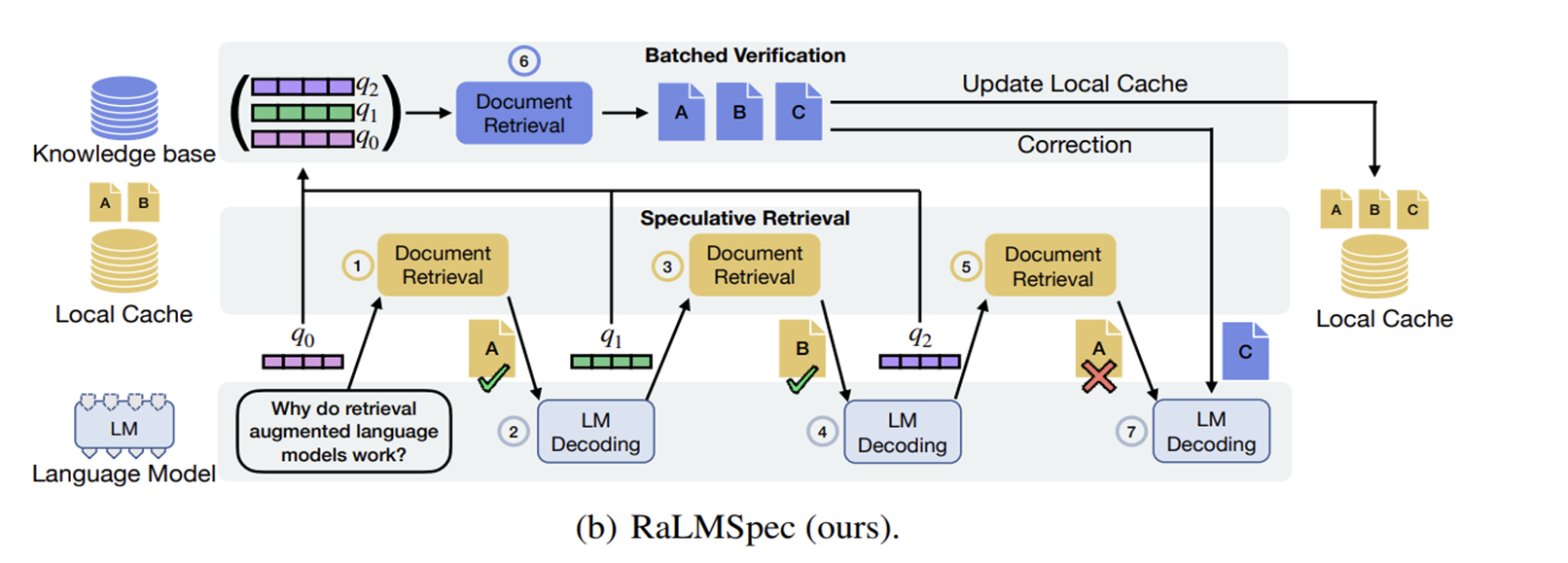
对此,作者等人想到,可以推测一部分可能会用到的文献,提前存放在本地缓存中(这就是Speculative的地方),在本地缓存中查找文档与在知识库中查找文档的方法相似,但由于本地缓存的文档数远远小于知识库中的文档数,因此,查找会变得非常快速(这就是Speculative Retrieval)。
具体来说,RaLM有一个本地缓存,如果这个本地缓存是空的,就进行一次Initial Query,查找一些文档放入其中。随后查找的时候就只从这个缓存里面查找了。
但是本地缓存毕竟不是知识库(除非它有着和知识库几乎一样的文档,但是这样就没意义了),所以这样子查找会出错。作者们想到了一个法子,可以先查s个文档,然后再批量对这些文档进行验证(也就是从知识库批量对比这些文档是不是最相似的那些,这就是Batched Verification),如果发现某s个文档中的第i个文档出错了,就回滚到第i个文档,然后代之以正确的文档并将之加入到本地缓存里,随后再用新的文档生成新的prompt。这里的s被称为推测步长,而且s要取一个比较好的值,如果s太短,比如我们让s=1,那每从本地缓存里查出来一个文档,就要从知识库里查这个文档对不对,不管用不用这个方法,每查一次文档都要上一次知识库,那这岂不是白用这个方法了(笑);如果s太长,假如s=114514,但s从第二个开始就错了,那后面的114512个文档就白查了。至于怎么取,后文有所介绍。
此外,检索步骤和验证步骤可以异步进行,这样效率会更高。
现在我们来说一说s是怎么实现的,作者们称这个方法为Optimal Speculation Stride Scheduler(OS3),它能自动地确定最好的s。原理是这样的:
至于这个数学期望是怎么算出来的,就超出我的理解范围了(叹气)。
但是事情到这里还没有完,我们之前定义了三个参数,现在我们要讨论怎么估计它们了。对于a和b,可以直接依靠RaLM最近的表现来预测。但对于γ(X),我们需要用到对数最大似然估计。作者们所用的式子是这样的:
无论如何,我们已经有办法确定最优步长s了。下面就是RaLMSpec的流程:

他们先进行3个Speculative Retrieval(i.e. q0, q1, q2, 所查询到的文档为A, B, A),随后对这些文档进行批量验证,在这里,q3所对应的A出错了(其实应该是C),所以将之修改为C,并将C存入到本地缓存中,然后重新进行LM Decoding环节。更精确的说,这段过程的伪代码是这样的:
1: Input: Input tokens X = {x0, x1,... , xt−1}, external corpus C, language model f(·)
2: Output: RaLM generated outputs
3: Initialize local cache Q = {}, speculation stride s, model generation stride k
4: q = encode(X), Q.insert(C.retrieve(q)) ▷ cache prefetching
5: while EOS not in X do
6: for i = 1 to s do
7: qi = encode(X),ˆdi = Q.retrieve(qi) ▷ speculative retrieval
8: Xˆi = f(X, ˆdi, k) ▷ model generation step that generates k new tokens
9: X = [X, Xˆi]
10: end for
11: d1,... , ds = C.retrieve(q1,... , qs) ▷ batched verification
12: m = arg miniˆdi != di
13: if m ≤ s then ▷ do correction if needed
14: Roll X back to the m-th speculation step
15: Xˆ = f(X, di, k)
16: X = [X, Xˆ]
17: end if
18: end while大体上来说,这段代码主要是在:初始化本地缓存,并进行初始预取。在主循环中,进行推测性检索和生成新的token。每经过s次推测后,进行批量验证。如有需要,进行校正,确保生成结果的准确性。直到生成结束符 (EOS),生成过程结束。
评估:
实验设置如下:
•LLMs: GPT2-medium, OPT-1.3B, LLaMA-2-7B. 对于KNN-LM服务,采用了16 layers, decoder-only, 247M的LLM
•Datasets:
•四个 QA 数据集:Wiki-QA、Web Questions、Natural Question, Trivia-QA;
•外部知识库: Wikipedia Corpus;
•KNN-LM评估: Wikitext-003.
•Retrievers:
•Exact Dense Retrievers(EDR): Dense Passage Retriever(DPR);
•Approximate Dense Retriever(ADR): DPR-HNSW;
•Sparse Retriever(SR): BM25 Retriever.
•Baseline:
•Naïve Iterative RaLM: 使用RaLMSeq作为基准,在每个LLM生成4个token后执行检索;
•KNN-LM:对生成的每个token执行检索.
评估结果:
- RaLMSpec对EDR提升效果最显著,OS3对ADR,SR的提升作用最大


2. EDR使用较大步长效果较好,但ADR则需要使用OS3。


3. EDR相较ADR和SR表现较好,在1.70x~1.85x.
